「我在Reddit的某个社区提到用SQLite做知识库,直接被围攻了。」Brad在Latent Space的Builder's Club分享会上笑着说。
这场争论的背后,是一个更本质的问题:当我们试图让AI记住更多上下文时,应该用什么方式存储?扁平文件、图数据库、还是SQLite?
争论的起点:文件夹还是数据库?
过去两年,关于「知识管理」的宗教战争一直在升温。一派坚持用Obsidian这样的Markdown文件系统,强调简洁和可读性。另一派主张用Neo4j这样的图数据库,强调关系遍历和复杂查询。
但Brad发现了一个尴尬的事实:那些坚持用文件夹的人,最终都在不知不觉中重新发明了一个「劣质数据库」。
他给出了一个经典例子:「当你需要给笔记建立索引,需要维护标签关系,需要全文搜索——你已经在做数据库该做的事了。只不过你用的是效率更低的方式。」
这不是理论推演。Brad自己构建了一个名为WikiBase的项目,用SQLite支撑起Builder's Club社区的所有知识沉淀:播客转录、嘉宾信息、技术讨论、成员偏好——全部存在一个关系型数据库里。
为什么是SQLite,而不是Neo4j?
图数据库听起来很酷。Neo4j的节点遍历、Cypher查询语言,确实能优雅地处理复杂关系。但Brad测试后发现:对于大多数场景,这是过度工程。
「我试过Neo4j,也写过Cypher查询。但当我拿同样的场景在SQLite上跑时,发现根本不需要那么复杂。」
他给出了三个关键理由:
**第一,大部分知识管理场景不需要深度遍历。**你不会频繁地查询「与某篇笔记距离三度以内的所有相关内容」。更常见的需求是:给定一个主题,找出所有直接相关的节点。这用SQLite的JOIN就能搞定。
**第二,SQLite的结构约束更有价值。**关系型数据库强制你定义清晰的Schema——这听起来像限制,实际上是设计压力。它逼着你思考:什么是节点?什么是边?什么是属性?这种思考本身就是知识整理的过程。
**第三,AI时代的数据库操作已经足够简单。**以前写SQL需要记复杂的语法。现在你只需要告诉Claude:「帮我查询所有提到Kubernetes的播客节点」,它会自动生成正确的查询语句。图数据库的学习成本优势不再明显。
有人在聊天中提到:「那什么时候才需要图数据库?」
Chase给出了一个真实案例:他用Helix(一个支持图查询的数据库)做任务依赖管理。当一个AI agent要选择下一个任务时,需要遍历整个依赖树,计算每个任务与当前任务的「距离」——这种场景下,图遍历就成了刚需。
但Chase也承认:「我选Helix主要是因为觉得它很酷,想试试看。不是因为它真的比SQLite好。」
关键不是数据库类型,而是描述质量
Brad展示WikiBase架构时,停留最久的不是数据库设计,而是一段Prompt。
这段Prompt的任务很简单:给每个新录入的节点生成一段描述。但它的措辞极其严格:
「如果这是一个播客,你必须在描述的第一句话说清楚:这是一个播客节目。如果这是一个想法,你必须明确说:这是一个关于XX的想法。」
Brad反复强调:「这是整个系统的关键。如果描述不够明确,后面所有的检索都会崩掉。」
为什么?因为AI在填充上下文窗口时,完全依赖这些描述来判断「这个节点是否相关」。如果描述模糊,检索结果就是一团糟。
他展示了一个正面例子:
「这是一个Latent Space播客节目,嘉宾是Dylan Patel,Semi Analysis的CEO。在这期节目中,Dylan边做饭边讲解了AI芯片战争的底层逻辑。」
这段描述包含了四个关键信息:内容类型(播客)、人物身份、核心话题、独特场景。任何一个维度的检索都能精准命中。
相比之下,糟糕的描述长这样:
「本内容讨论了AI领域的相关话题。」
这种描述等于没说。
知识库的真正价值:让AI记住你
WikiBase最有意思的功能不是存储播客转录,而是记录成员的交互历史。
当你第一次在Discord里使用/join命令时,你的Discord信息会被写入数据库,成为一个「节点」。之后你每次跟Bot对话、参加分享会、提问题,都会在数据库里留下「边」——连接你和特定话题的关系。
Brad举了一个例子:「上周Yagiz分享了Anthropic的Moldbook话题。如果下周有人问起类似问题,Bot会自动@Yagiz,说『这个问题上周Yagiz讲过』。」
这不是简单的关键词匹配。Bot会读取Yagiz的节点信息,看到他讲过的主题、使用的工具、偏好的沟通方式,然后判断他是否适合回答这个问题。
更进一步,成员可以主动告诉Bot自己的偏好:「我不喜欢冗长的解释,直接给我代码」。这些偏好会存在数据库里,影响Bot未来的回复方式。
这就是真正的「个性化上下文」。不是每次对话都要重复自我介绍,而是AI真的记住了你。
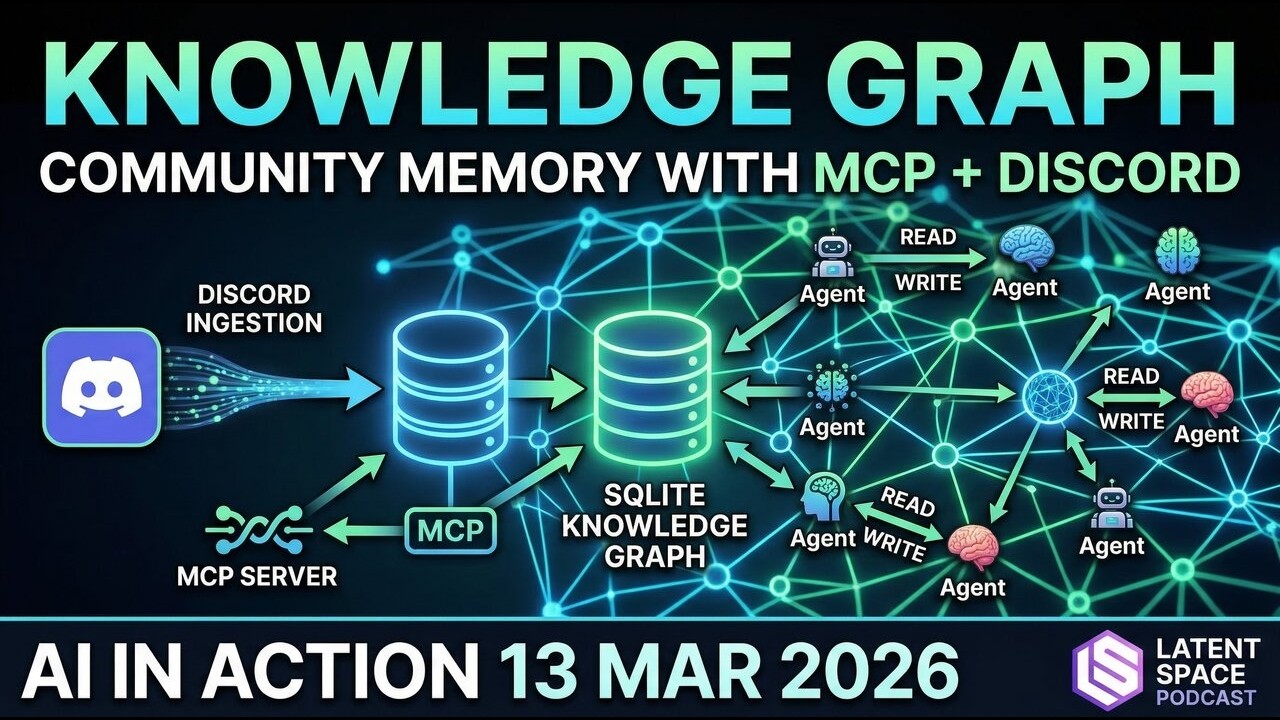
数据管道:从RSS到知识图谱
WikiBase的数据流分为两端:
**左侧是自动摄取。**每小时运行一次Cron任务,检查Builder's Club的YouTube频道和文章RSS。新内容进来后,系统自动提取标题、转录、时间戳,存入nodes表。然后跑一遍实体抽取——识别出演讲者、提到的工具、讨论的话题,把它们作为节点存入数据库,并创建edges表里的关系记录。
**右侧是人工交互。**成员通过MCP Server或Discord Bot与知识库对话。Bot会读取skills文档(存在数据库里的操作指南),知道如何查询、如何写入、如何维护关系。所有对话历史也会被记录,成为未来检索的一部分。
Brad特别强调了「非均匀结构」的价值。不是所有节点都平等。播客节点会被分chunk,每个chunk单独存储、单独embedding——这样当用户问「Yagiz提到的那篇论文是什么」时,能精确定位到转录里的某一段。
而嘉宾节点只需要一个总结性描述,不需要细粒度切分。
这种「详略分明」的设计,让检索效率提升了一个量级。
三种索引,三种速度
WikiBase同时维护了三种索引:
- 向量索引:用于语义搜索。当用户问「有没有关于AI agent协作的讨论」时,embedding模型会找到语义相似的节点。
- FTS5全文索引:用于精确匹配。当用户问「哪期播客提到了Kubernetes」时,直接在转录文本里搜。
- B-tree索引:用于关系查询。当用户问「Kevin参与过哪些分享」时,直接查edges表。
三种索引各司其职,但都指向同一个nodes表。这就是关系型数据库的优势——你可以在不同维度建立索引,而不需要复制数据。
Brad笑着说:「图数据库也能做到这些。但SQLite更轻量,更容易debug。出了问题,你可以直接用DB Browser打开数据库文件,看看里面到底存了什么。」
未解的问题:如何让AI不说废话
分享的最后,Brad提到了一个他还没解决的问题:diarization(说话人识别)。
现在WikiBase从YouTube抓取转录时,只能拿到一整段文字,分不清谁说了什么。这导致当用户问「Brad说过什么关于SQLite的观点」时,Bot只能返回整段转录,让用户自己找。
技术上可以做diarization,但Brad发现「这事儿的麻烦程度远超预期」。他需要把音频切片、识别声纹、匹配时间轴、再回填到数据库——这套流程在商业项目里他试过,最后放弃了。
有人建议:「你可以让AI读转录,推测每句话是谁说的。」
Brad摇摇头:「试过。准确率感人。尤其是多人对话,AI经常把发言对象搞混。」
这个问题还没完美答案。但Brad说,这恰恰是开源的价值——他把WikiBase的代码放出来了,如果社区里有人想挑战这个问题,欢迎来提PR。
为什么要建这个东西?
有人问了一个本质问题:「你为什么要花这么多时间搞这个?」
Brad的回答很实在:「因为我每天都在消费这些内容。播客、技术分享、Discord讨论——这些东西如果不沉淀下来,三个月后我就完全忘了。」
他不是在建一个「知识管理工具」,而是在建一个「记忆外挂」。
Kevin补充了一个观点:「接口已经变了。以前我们用文件夹和标签整理知识,因为我们需要『看到』那些文件。现在我们用AI对话,知识怎么组织不重要,重要的是能不能快速填进上下文窗口。」
这话让我想起Dan Norman在《设计心理学》里的概念:knowledge in the world vs. knowledge in the head。
以前,我们把知识放在「世界里」——书架上、文件夹里、笔记本里。我们需要记住这些知识在哪里。
现在,我们把知识放进AI的上下文窗口里。我们不需要记住在哪里——我们只需要会问。
SQLite、Neo4j、Obsidian,这些工具之间的争论,最终会被这个范式转变消解掉。
真正重要的问题只有一个:当AI需要上下文时,你能多快给它准备好?