Brandon Harvey在跑步机上调试完音频,开门见山抛出一个结论:「我觉得现在的Agent规划模式都挺糟糕的。」
这话不轻。他在Meta和多家创业公司做过工程师和产品经理,最近几个月全职做Vibe Coding,连续遇到同一个问题——当你让Agent执行一个中等规模的项目时,它要么生成一堆混乱的Markdown文件,要么把所有规划数据锁在自己的内部状态里,其他Agent实例根本访问不到。
问题出在哪儿?
他把软件开发生命周期拆成三个阶段:Spec(规格说明)、Backlog(任务待办)、Implementation(具体实现)。人类团队早就学会把这三件事分开管理。你会把PRD和Jira分开,会让任务看板独立于架构文档。
但今天的Agent,要么把Spec和Backlog混在一起,要么用Markdown文件硬撑,结果就是一团浆糊。
「当你的子Agent早上醒来,它得在20到50个Markdown文件里找方向。」Brandon说,「这太蠢了。」
为什么Agent需要结构化任务系统
Brandon的观察来自实战。他这几个月一直在开发一个跨平台的进程间通信库,要覆盖Windows、Linux、macOS,同时提供Rust、C、Go、Node四种语言接口。组合爆炸出20多个构建目标。
这种项目如果让Agent自己管理计划,你会看到它迷失在自己写的文档森林里。
他总结出结构化任务系统的几个核心价值:
1. 并行化有了基础
当任务之间有明确的依赖关系(A必须在B之前完成),你就可以让多个Agent同时工作。它们各自认领ready状态的任务,互不冲突。
2. 验收条件可以分离
每个任务可以有独立的测试要求。不是「整个Epic完成后再说」,而是「这个任务做完,必须满足这三个条件」。
3. 检查点变得可视化
你不用读代码,看一眼任务列表就知道进度:哪些完成了,哪些在进行,哪些被阻塞了。
4. 子Agent有了清晰的工作单元
它醒来时不需要「理解整个项目」,只需要知道:「我现在要做的是这个任务,验收标准是这些,依赖关系是那些。」
但这个思路不是他发明的。
Steve Yegge的Beads:好主意,糟糕的实现
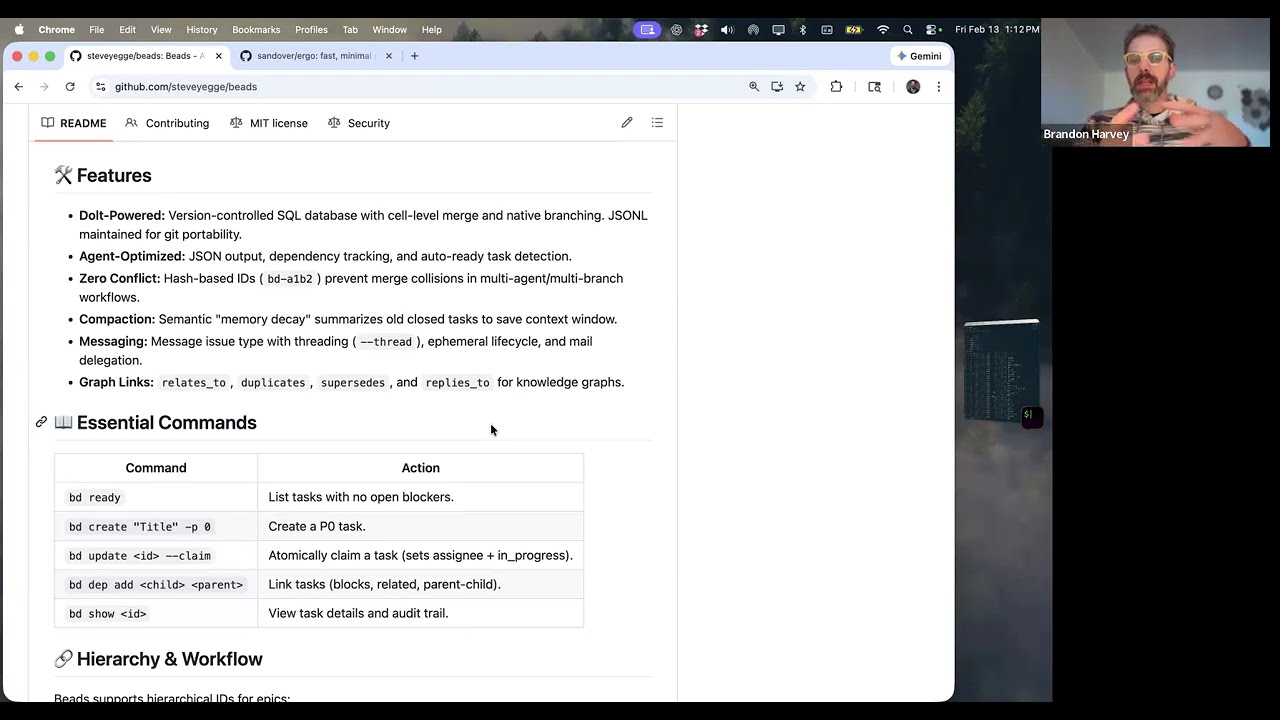
Brandon提到Steve Yegge——Google和Amazon的OG工程师,博客写得又长又有见地。Yegge诊断出了这个问题,并创建了一个叫Beads的项目。
Beads的核心思路很简单:在你的项目根目录运行bd init,然后告诉Agent「用这个做任务追踪」。Agent就会把任务写成结构化数据,存在本地的.beads文件夹里,就像你在项目里嵌入了一个本地Jira。
这个想法很美好。
但实现让Brandon抓狂。
他打开Beads的帮助文档,滚了五页还没翻完。这个项目同时维护一个SQLite数据库和一个JSONL文件,每5秒同步一次。有后台守护进程。有版本兼容问题——你打开两周前的旧项目,Beads会告诉你数据库格式过时了,无法更新。
「Beads是个糟糕的项目,」Brandon直接说,「但Yegge的想法是对的。」
所以他花了两个月,用Go重写了一个极简版本:Erggo。
Erggo:一个JSONL文件,搞定所有事
Brandon从来没写过Go。
但在Vibe Coding时代,这不重要。他用AI写了Erggo,测试覆盖率超过他职业生涯所有项目的总和。
Erggo的设计哲学是极简:
1. 纯文本,无数据库
所有任务存在一个erggo/events.jsonl文件里,一行一个事件。创建任务是append,修改状态也是append。除非你手动运行erggo compact或erggo prune,否则你永远不会丢失数据。
没有SQLite。没有守护进程。不会有「数据库格式过时」这种事。
2. 并发安全,极简锁机制
用简单的文件锁处理并发。Brandon实测过,同时跑4个Agent写同一个任务文件,偶尔有冲突,但Agent能轻松解决JSONL的合并冲突。
3. CLI足够简洁
只有少量命令:erggo add创建任务,erggo set修改属性,erggo claim认领任务,erggo sequence设置依赖关系。
其他操作?都是erggo set的不同参数。没有set-title、set-description这种臃肿命令。命令数量少,测试面小,模型学习快。
4. 对Git友好
你可以把erggo/文件夹加入.gitignore,也可以提交它。Brandon倾向于提交——在完成一个Epic时,顺便提交一次任务状态更新。
不同分支会有不同的任务状态,但合并时Git处理行级差异,Agent能轻松解决冲突。
一个真实的工作流
Brandon现场演示了一遍。他打开Codeex(一个AI编码工具),选了最快的Spark模型,给它一个指令:
「学习erggo-help的内容,为Erggo规划一个新功能:加入cowsay支持。」
他笑着解释:「cowsay是我临时想的例子,我本该准备一个真实需求的。」
Codeex Spark有时候会理解偏差。它第一次输出时说「我知道怎么做了」,但没有实际写任务。Brandon纠正它:「你应该用Erggo命令写出来。」
几秒后,任务列表出现了:
E Add cowsay feature
O Define feature requirements
O Design CLI interface
O Implement cowsay renderer
O Write tests
· Update documentation
E开头的是Epic(特性组),O是ready状态(可以开始做),小圆点是pending(有依赖关系,还不能做)。
Brandon运行erggo show查看第一个任务的详细内容:
Task: Define feature requirements
**Acceptance Criteria:**
- Feature scope documented
- CLI interface design completed
- Integration points identified
**Automated Validation Gates:**
- Requirements markdown file exists
- Contains at least 3 sections
这个结构不是Erggo强制的,是Brandon在自己的agents.md配置文件里要求的。他有一条指令:「写任务时,请包含Acceptance Criteria和Automated Validation Gates两个部分。」
Automated Validation Gates这个概念很关键。它告诉Agent:「你不需要每次都停下来问我『这样对吗』,除非这个门无法自动验证。」
多Agent并行:人类成为瓶颈
有人在聊天窗口问:「你最多同时跑过几个Agent?」
Brandon说最多4个。
不是因为Erggo扛不住,而是因为他自己的上下文切换能力到极限了。
他早上在调Windows的构建脚本,切到Linux测试C API绑定,再切到macOS处理Node模块的签名问题。10分钟后回到第一个对话窗口,他得先问Agent:「用通俗的语言解释一下,咱们现在在干什么?」
「我会让模型给我讲讲,这些hooks、gates、smoke tests都是什么意思,」他说,「因为我已经忘了。」
Steve Yegge写过一篇文章叫《AI Vampire》,核心观点是:你一天能深度思考的事情是有限的。上下文切换会榨干你的认知带宽。
Brandon的解决方案是在不同场景使用不同模型温度:
- 探索性的Spec阶段:用Claude Opus或Gemini,开高温,来回辩论
- 规划阶段:用Codeex高推理模式,让它生成详细的任务拆解,然后让另一个模型审查
- 执行阶段:用中等模型(53 medium),按任务列表一个个实现
他提到一个模式:「Measure twice, cut once」(两次测量,一次切割)。
具体来说,Spec写完后,让一个Agent规划任务,再让另一个模型从CTO或Staff Engineer的视角审查这个计划。几乎每次,第二个模型都能提出有价值的改进。
争议:为什么不用SQLite?
聊天窗口有人质疑:「SQLite明明很好用,为什么你要用JSONL?」
Brandon解释:「SQLite很棒,但我不想把SQLite数据库提交到Git仓库,只是为了追踪任务。」
他的逻辑是:
-
Git是行级差异工具。JSONL一行一条记录,Git天然支持,合并冲突容易解决。SQLite是二进制格式,合并冲突是灾难。
-
文本是最终接口。一百年后,你依然能读懂JSONL文件。数据库格式会过时,但纯文本永远有效。
-
Agent擅长处理文本。当出现合并冲突时,Agent能直接读JSONL,理解冲突,写出正确的合并结果。
有人追问:「Erggo的存储是项目级别的,还是跨项目的?」
Brandon回答:默认情况下,Erggo在项目根目录找.erggo/文件夹。但你可以用--dir参数指定其他位置。如果你想跨项目共享任务列表,理论上可行,但他没这么做过。
一个隐藏的陷阱:任务完成了,但目标没达到
Brandon提到一个他踩过的坑。
有时候Agent在执行一个Epic的过程中,会发现一些新的信息,导致最终的目标实际上跟最初规划的有偏差。所有任务都标记为完成了,但回头一看,「咦,我们要做的事情好像没做完」。
这不是工具问题,是规划本身的问题。
他的应对方式是:在Epic进行到一半时,主动问Agent:「这个计划还能达成我们最初的目标吗?还是需要调整?」
通常Agent会意识到有些横切关注点(cross-cutting concerns)冒出来了,需要补充新的任务。
这也是为什么他倾向于提交任务状态——它是一种历史记录,你能看到规划是怎么演化的。
Erggo的设计权衡
Erggo目前稳定了。Brandon最近两个月没加过新功能。
有人问:「Erggo的Roadmap里还有什么?」
他说没有了。「这个工具做好一件事,做稳了,就够了。就像经典的Unix工具,ls、grep,它们几十年不变,因为已经对了。」
不过他也坦诚:「这个工具的保质期可能只有3到6个月。最终Agent框架会把这套能力内置进去。」
他认为这没问题。「我自己用得爽,写得也开心。它消失的时候,会有更好的东西。」
聊到最后,有人问:「你觉得work tree(Git的工作树功能)怎么样?」
Brandon停顿了一下,说:「我觉得work tree还不够成熟。我试过几次,被绊倒了,就放弃了。」
但他很快补充:「不过理论上,Erggo应该能跟work tree配合。因为本质上是Git的分支合并逻辑,Agent能处理。」
尾声
Brandon分享了他的Erggo技能配置文件(一个预设Prompt模板)。在这个配置里,他定义了任务应该怎么写、Epic应该怎么组织、验收条件应该包含什么。
他说:「这样,我就可以在任何项目里运行/erggo,Agent就知道怎么做了。」
这套方法论的核心不是Erggo本身,而是一个认知:
Spec、Backlog、Implementation是三个不同的阶段。你可以用不同的模型、不同的策略来处理它们。不要把它们混在一起。
David(另一位参会者)在聊天窗口打字:「我喜欢你说的『分层次看结构』。Feature是5000英尺高度,Epic是标题层,Task是段落层,Task Body是细节层。Markdown文件只有一个层次——要么打开全读,要么不读。」
Brandon回复:「就是这个意思。」
会议结束时,主持人说:「下周David会讲他怎么把所有开发搬到Discord和手机上,用work tree + OpenClaw实现自动化dev server。」
Brandon笑着说:「听起来很疯狂,我很期待。」
屏幕黑了。但Erggo的GitHub仓库在接下来的一周里,收到了20多个star。